Is a Taxonomy of Climate Misinformation Helpful?
1. Global warming is not happening
2. Human Greenhouse gases are not causing global warming
3. Climate impacts are not bad
4. Climate solutions won’t work
5. Climate science is unreliable
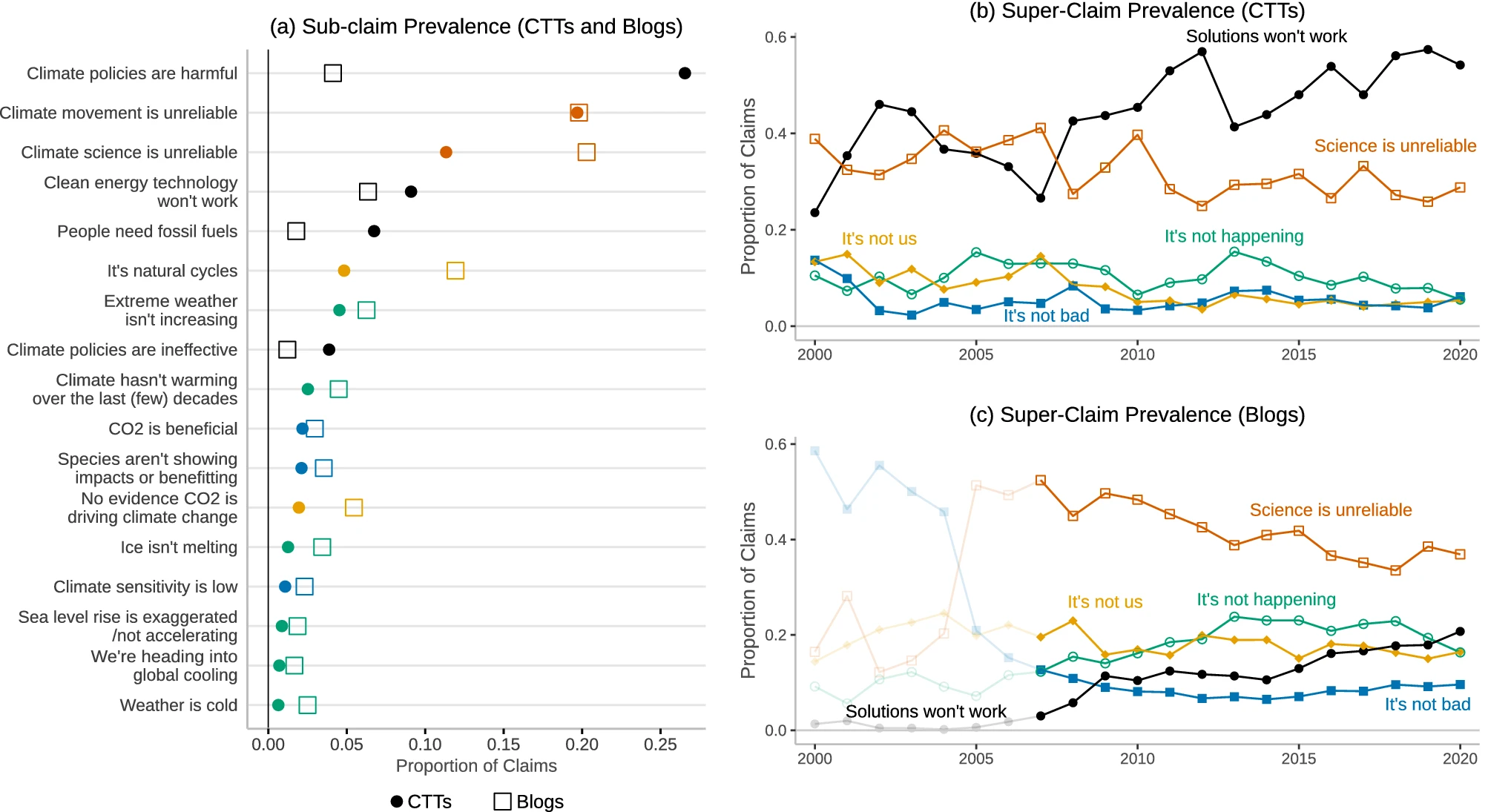
The sub- and sub-sub- claims are positions used to justify the larger “super” claims. It’s important to note that some of these may be truthful claims, but they are used inappropriately to justify the false “super claim.” For instance, “we need energy” (4.5) is true, but it serves as a subcategory of claims used to justify the claim that climate solutions won’t work. Likewise, “nuclear is good” (4.5.3) is a position that is held by many people who are otherwise not contrarian (including myself) - but it’s a claim that is used falsely to justify the false “super-claim.”
The authors developed a computer model to help with classifying content from CBs and CTTs. This allowed the authors to track how CBs and CTTS differ from each other, and it also provides the ability to see trends in the types of misinformation promoted by each over time. The end results indicate that CTTs tend to focus more on the claims that climate science is unreliable (5) and that solutions won’t work (4) while CBs tend to focus on more heavily on the claim that climate science is unreliable. There’s an increasing trend in both to claim that solutions won’t work.
The full paper is available online without a paywall.[1] One of the authors also has written a helpful description of the paper.[2] And Ken Rice, who helped train the model, has also offered his perspective on the paper and responded to some of the objections to it.[3] The largest concern I’ve seen so far is that this may lead to censorship of misinformation. This is a valid concern, I think, but that's not so much a fault of the paper's findings as much as it is a (perhaps justified) fear over how this model might be used. People are free to publish misinformation, and those who are informed are free to call it out as such, but I believe we need to protect the right to misinform in order to safeguard the right to free speech that we all have to issue corrections to wrong but widely-held opinions.
I also think to be even-handed, the model should be trained to identify exaggerations of climate alarm. We are seeing organizations claiming that AGW will lead to the extinction of the human species within decades, yet to my knowledge credible science does not back up that claim. Other organizations talk exaggerate the impacts of tipping points. Still others claim that many of the worst impacts of AGW are not inevitable, so it won't do any good to transition to net-zero emissions. These claims can be just as destructive as the "denialist" claims, but there is no part of the taxonomy for them. And the model was trained against "conservative" think tanks, while climate misinformation is not limited to think tanks of a conservative nature.
Nevertheless, it's clear that fact-checkers cannot keep up with the proliferation of misinformation. If one article gets flagged by ClimateFeedback on Facebook, a dozen other articles can simply repeat the claims of the first, and the misinformation continue without being flagged. The use of an algorithm that can flag these posts in "real time" will help networks keep up with the proliferation of misinformation. However, the use of an algorithm like this to flag misinformation suffers from the weakness that no person is actually reading the article, so there are going to be a higher percentage of type 1 and type 2 errors. Articles will be flagged wrongly or may not be flagged wrongly. No amount of flagging will eliminate our need to be skeptical about what we read on line. At best, this algorithm may be useful to offer a caution to readers along with links to helpful articles that are likely to be relevant to what was flagged.
It's one thing to be speeding and then get pulled over by a police officer who clocked you, pulled you over, and personally handed you a ticket. It's another to be ticketed by an an automated speed trap. These automated systems simply send you a ticket based on the speed of your car without considering why you were speeding or even who was driving. The ticket may issue a fine but with no points, since the automated ticket can't verify who was driving the vehicle. The "flag" is less severe because of the built-in limitations of the automated system. I hope if this model is widely implemented on some place like YouTube or Facebook, this is taken into consideration.
[1] Coan, T.G., Boussalis, C., Cook, J. et al. Computer-assisted classification of contrarian claims about climate change. Sci Rep 11, 22320 (2021). https://doi.org/10.1038/s41598-021-01714-4
[2] “Climate change: How machine learning holds a key to combating misinformation” https://lens.monash.edu/@politics-society/2021/12/08/1384230/climate-change-how-machine-learning-holds-a-key-to-combating-misinformation
[3] …and then there’s physics. “Classification of contrarian claims about climate change”
https://andthentheresphysics.wordpress.com/2021/12/11/classification-of-contrarian-claims-about-climate-change/



Comments
Post a Comment